



Most conversational AI builds fail not because of model capability. They fail because critical technical questions were never formally resolved.
Conversational AI design best practices are not a checklist — they are architecture decisions. Teams that skip them build agents that perform in demos but not production.

This article delivers the framework to resolve each one before building begins.
The Architecture Decision That Shapes Everything Else
Every conversational AI program begins with an architecture choice — and most teams make it by default rather than by design.
The three main approaches — rule-based, LLM-only, and RAG-powered — each carry fundamentally different tradeoffs on accuracy, maintenance cost, and integration depth.
What RAG actually means
RAG (Retrieval-Augmented Generation) connects the language model to your organization’s live knowledge bases, grounding responses in verified data rather than model assumption.
According to Grand View Research, the enterprise RAG market is growing at 49.1% CAGR through 2030 — because accuracy requirements in regulated and customer-facing domains make it the only viable production architecture.
- High-stakes domain accuracy: any context where a hallucinated response carries regulatory, financial, or brand liability — financial services, healthcare, legal, and retail at scale
- Live data dependency: the agent needs to answer questions about real-time state — inventory, order status, account data, policy updates — not cached training knowledge
- Multi-market deployment: culturally and linguistically diverse user bases where response grounding prevents market-specific accuracy drift
- Extensibility requirement: the system must add new channels, domains, or data sources without re-training or re-platforming the model layer
Data infrastructure prerequisites before RAG integration begins:
- Structured, versioned knowledge base with ownership assigned
- Defined document retention and freshness policy
- Access control layer governing what data each user context can retrieve
- Chunking and metadata strategy that supports semantic retrieval
- Evaluation set for retrieval precision before build begins
Choosing the wrong one for the domain is a decision that cannot be undone without re-platforming, as the RAND Corporation’s AI failure analysis confirms is the most expensive mistake in production AI programs.
| Dimension | Rule-Based | LLM-Only | RAG-Powered |
| Language understanding | Keyword matching — brittle | Semantic, broad | Semantic + grounded in live data |
| Maintenance burden | High — manual script updates | Low — model handles variation | Medium — knowledge base governance |
| Accuracy: regulated domains | Low — fails on edge cases | Medium — hallucination risk | High — retrieval-verified responses |
| Integration depth | Shallow — rigid API triggers | Shallow — model assumptions | Deep — live data source connections |
| Best fit | Simple FAQ deflection only | General assistants, low stakes | Domain-specific enterprise agents |
Intent Design — Engineering for What Customers Mean, Not What They Type
- Most teams design for utterances: the exact phrases users might type.
- High-performing teams design for intent clusters: the full semantic range of how a single customer need can be expressed across real populations, including stressed, distracted, and non-native users.

Intent design is the technical process of mapping what users mean to what the system does — and it is where the majority of conversational AI failures originate.
- Define the intent taxonomy: document which interactions the agent resolves, clarifies, escalates — before a single utterance is written or a model is selected
- Collect real utterance data: pull from existing support logs, chat transcripts, and search queries — not invented examples — to build training sets that reflect actual language
- Build for variation, not canon: for each intent, generate utterance variants covering paraphrase, typo, abbreviation, and emotional register — the model must handle all of them
- Set confidence thresholds: define the score below which the agent asks a clarifying question rather than guessing, and the score below which it escalates to a human
- Map every fallback before launch: for each unmatched intent, define a specific recovery path — not a generic error — that rebuilds user confidence and offers a forward option
The table below shows how the three main NLP approaches compare on the dimensions that determine real-world intent resolution quality — and where each one breaks under production load.
| Approach | How it Works | Where It Breaks |
| Keyword matching | Triggers on specific words or phrases | Fails on synonyms, typos, phrasing variation |
| Intent classification | ML model clusters semantically similar inputs | Fails on compound or out-of-distribution queries |
| LLM-grounded intent | Language model interprets full conversational context | Needs domain boundary enforcement to prevent drift |
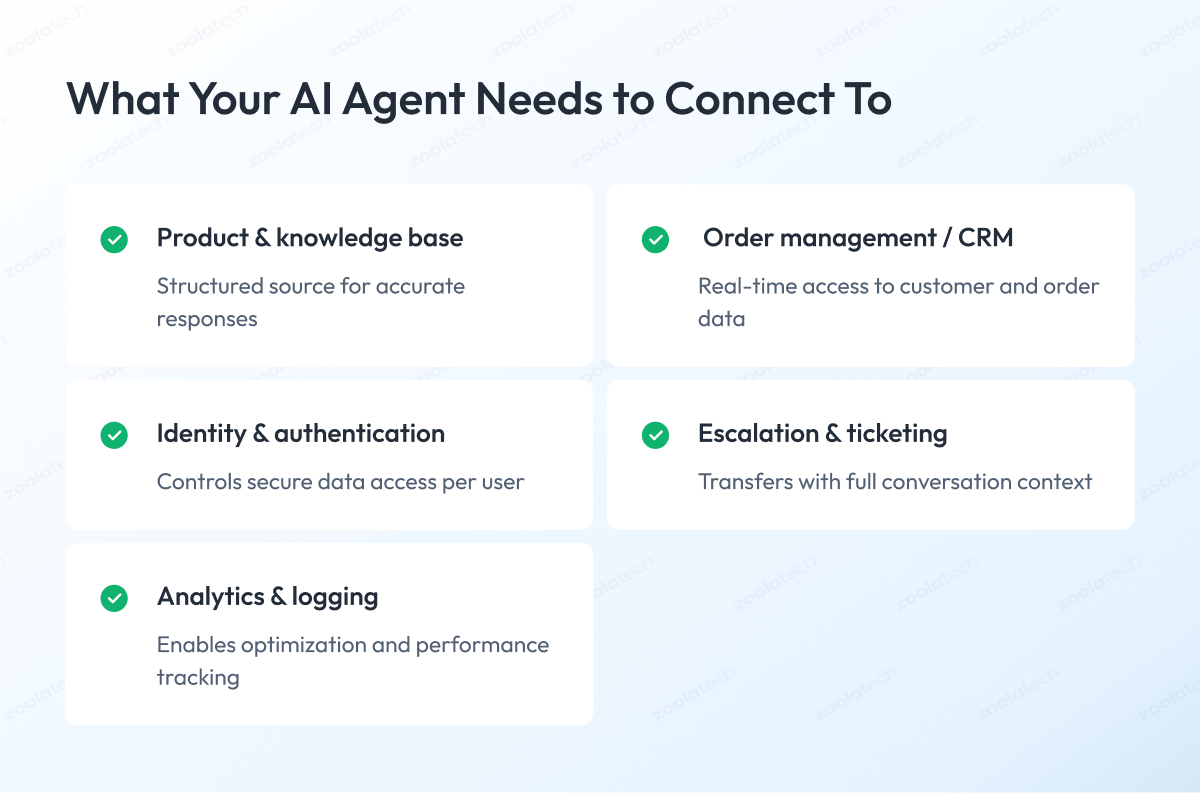
Data Integration — What Your Agent Needs to Connect to and Why
A conversational AI agent is only as accurate as the data it can access in real time. Grounding responses in live organizational data — rather than static model training — is what separates agents that perform in production from those that hallucinate under load.
86% of enterprises are already augmenting their LLMs with retrieval frameworks specifically because out-of-the-box models cannot meet accuracy requirements on domain-specific queries.
- Product or knowledge base: the agent’s primary resolution source — must be structured, versioned, and queryable at the chunk level for reliable retrieval
- Order management or CRM: for transactional queries about account state, order status, or history — requires real-time API access, not batch sync with latency
- Identity and authentication: determines which data the agent can surface to which user — access control must be enforced at retrieval, not post-generation
- Escalation and ticketing system: the handoff destination — must receive full conversation context, not just a transfer event, for human agents to resolve without restart
- Analytics and logging pipeline: conversation data that feeds continuous improvement — consistently omitted at build stage, consistently regretted within 90 days
Data quality must be validated before integration begins. A retrieval layer built on inconsistent, stale, or ungoverned data produces confident-sounding incorrect responses — which are harder to detect and more damaging to trust than obvious errors.
- Deduplication and version control applied to all source documents
- Ownership assigned for every data source the agent queries
- Freshness SLA defined — how often each source must be updated
- Sensitivity classification applied before any data enters the retrieval layer
- Baseline precision test run before integration is marked complete
Brand Voice as a Technical Constraint — Not a Style Guide
Most teams treat brand voice as a design brief handed to the LLM as a system prompt. That approach works in controlled demos and fails in production — because system prompts alone cannot enforce tone consistency across millions of dynamically generated responses at conversational scale.
- Persona specification layer: documented voice parameters embedded in every generation call — not appended as post-processing or left to default model behavior
- Tone variation by scenario type: technical parameters governing response style separately for transactional queries, complaint handling, discovery flows, and upsell moments
- Prohibited output patterns: explicit constraints on phrasing, response length, and register enforced at the generation layer — not caught post-generation by human review
- Voice regression testing: automated checks that flag responses drifting from documented voice parameters before they reach users in production
Testing Conversational AI — Why Standard QA Misses Half the Failures
Conversational AI requires a fundamentally different testing approach from conventional software — because the failure modes are different.

A unit test confirms the code runs; it does not confirm that a frustrated customer at 11pm receives a response that holds brand integrity and resolves their query.
- Intent coverage testing: every defined intent is resolved correctly across high-variation utterance sets — not just canonical examples written by the team that built the taxonomy
- Edge case and off-script testing: structured simulation of unexpected, compound, emotionally charged, and adversarial inputs — these are what standard QA skips and what production surfaces first
- Brand voice regression testing: automated checks for tone drift, prohibited phrasing, response length violations, and persona inconsistency — run before every release, not just at launch
- Cultural alignment testing: for multi-market deployments — back-translation testing surfaces semantic drift and culturally incongruent expressions before they reach users in any market
- Failure and escalation path testing: every fallback response and human handoff is validated under simulated load — including context completeness at the point of transfer to a human agent
Teams that rely on standard unit and integration testing alone for conversational AI typically discover gaps through customer complaints. The table below shows the most common signs that a QA approach is insufficient for production conversational AI.
- Testing only canonical utterances, not variant expressions
- No automated brand voice regression between releases
- Escalation paths tested manually, not under load
- No back-translation protocol for multi-market deployments
The Technical Questions to Resolve Before Build — Decision Framework
The highest cost in any conversational AI build is an answer that arrives after development is already underway.
These are the conversational AI design best practices and pre-build technical questions that must have documented answers before architecture is finalized.
- “Which architecture?” Rule-based, LLM-only, or RAG — and what data infrastructure is required to support the accuracy and integration requirements of the specific domain.
- “What is the intent taxonomy?” Defined scope of what the agent resolves, clarifies, and escalates — documented with confidence thresholds and fallback logic, not assumed from requirements.
- “Which live data sources does the agent access?” Integration map with API contracts, data freshness SLAs, access control requirements, and retrieval evaluation criteria confirmed before building begins.
- “How is brand voice enforced technically?” Persona specification layer, tone variation parameters by scenario type, prohibited output patterns, and automated regression testing protocol all documented.
- “What does failure handling look like in the stack?” Fallback responses, escalation triggers, human handoff context format, and load-tested recovery paths designed before dialogue writing begins.
- “How is the agent tested before launch?” Intent coverage, edge case, brand voice regression, cultural alignment, and escalation path testing plan agreed and resourced before build starts.
Measuring Technical Performance — KPI Framework
Business KPIs tell you what happened commercially; technical KPIs tell you why. Engineering teams running a conversational AI program with confidence need both layers.
The technical metrics must be defined and baselined before launch, not assembled retrospectively when performance falls short of expectations.
| Category | Metric | What It Reveals |
| Intent resolution | Intent match rate across utterance set | Whether NLP handles real-world variation |
| Hallucination control | Out-of-domain response rate | Whether domain boundaries hold under edge inputs |
| Escalation quality | Context completeness at human handoff | Whether escalation design works in practice |
| Brand voice | Tone compliance rate in automated regression | Whether voice parameters govern generation |
| Latency | P95 response time under production load | Whether architecture scales without UX degradation |
| Coverage gaps | Unmatched intent rate over 30 days | Where intent taxonomy has gaps to fill |
Zoolatech Expertise in Practice
Applying these AI-driven conversational design practices at the architecture stage is what produces outcomes that hold at production scale.
- Intent architecture defined before dialogue was written
- Brand voice embedded as a generation constraint, not a prompt
- Failure paths and escalation logic designed before build, not after
- Inclusive design enforced at the model layer, not post-processing
Credible case study: designing accurate multilingual support
Credible’s requirement was 24/7 multilingual support at scale — in a regulated financial domain where accuracy is a compliance requirement, not a UX preference.

The core technical challenge was preventing hallucination on loan eligibility and financial guidance queries while supporting mid-conversation language switching without context loss, as documented in Zoolatech’s capability brief for the engagement.
- LangChain preprocessing layer: every user message contextualized and scoped to verified domain data before it reaches the OpenAI model — preventing out-of-domain responses at the preprocessing stage
- Domain boundary enforcement: system-level constraints define the agent’s approved financial scope — speculative or out-of-scope guidance cannot be generated regardless of user input phrasing
- Multilingual context preservation: mid-conversation language switching supported without session reset, context loss, or accuracy degradation — a customer can begin in one language and continue in another
- Modular Python FastAPI backend: architecture designed for extensibility — new loan types, additional channels, and community platform integrations added without re-platforming the core model layer
Outcomes
- 24/7 multilingual support — zero headcount expansion required
- Eliminated response inconsistency at scale previously inherent in human-staffed support
- Extensible without re-platforming — new channels added post-launch
Conclusion
Most conversational AI failures are not caused by the model itself. They happen when architecture, intent handling, data access, and testing are treated as implementation details instead of system design decisions.
- Most failures come from skipped early decisions
- Demo success does not equal production readiness
- Strong teams design before they build
- Resolve early → lower cost, more flexibility
- Resolve late → higher cost, fewer options
Teams that define these decisions early build conversational AI that scales reliably in production. Teams that delay them end up redesigning under pressure, at significantly higher cost.
Questions You May Have
What are the key conversational AI design best practices?
Resolving the intent taxonomy, architecture selection, and failure path design before any dialogue is written or any model is selected — these three decisions determine more of the outcome than any other factor.
When to use RAG vs. LLM-only?
RAG is required when the domain demands accuracy on live or domain-specific data, when hallucination carries regulatory or brand liability, or when the agent must access real-time organizational systems.
NLP design vs. chatbot scripting?
Traditional scripting designs for specific utterances and breaks on any variation; NLP and conversational bot design trains for intent clusters — the full semantic range of how a need can be expressed — and governs what happens when inputs fall outside that range.
How is brand voice enforced?
Voice parameters are embedded as generation constraints — persona specification, scenario-specific tone variation, and prohibited output patterns — enforced at the model call level, with automated regression testing running against documented parameters before every release.
How do you test a conversational AI system before production launch?
A five-layer testing framework is required: intent coverage across utterance variations, edge case and off-script simulation, brand voice regression, cultural alignment via back-translation testing, and escalation path validation under production-simulated load.
What is the biggest technical mistake in conversational AI design?
Skipping the intent taxonomy — proceeding to dialogue writing and model selection without a documented map of what the agent resolves, clarifies, and escalates — which, according to the RAND Corporation’s AI failure research, is consistently the leading cause of production failure in AI programs.




















