Summary
Business challenge:
Developing data-driven reputation management tools using evolutionary biology and visualization, with a focus on accurately analyzing media content.
Zoolatech approach:
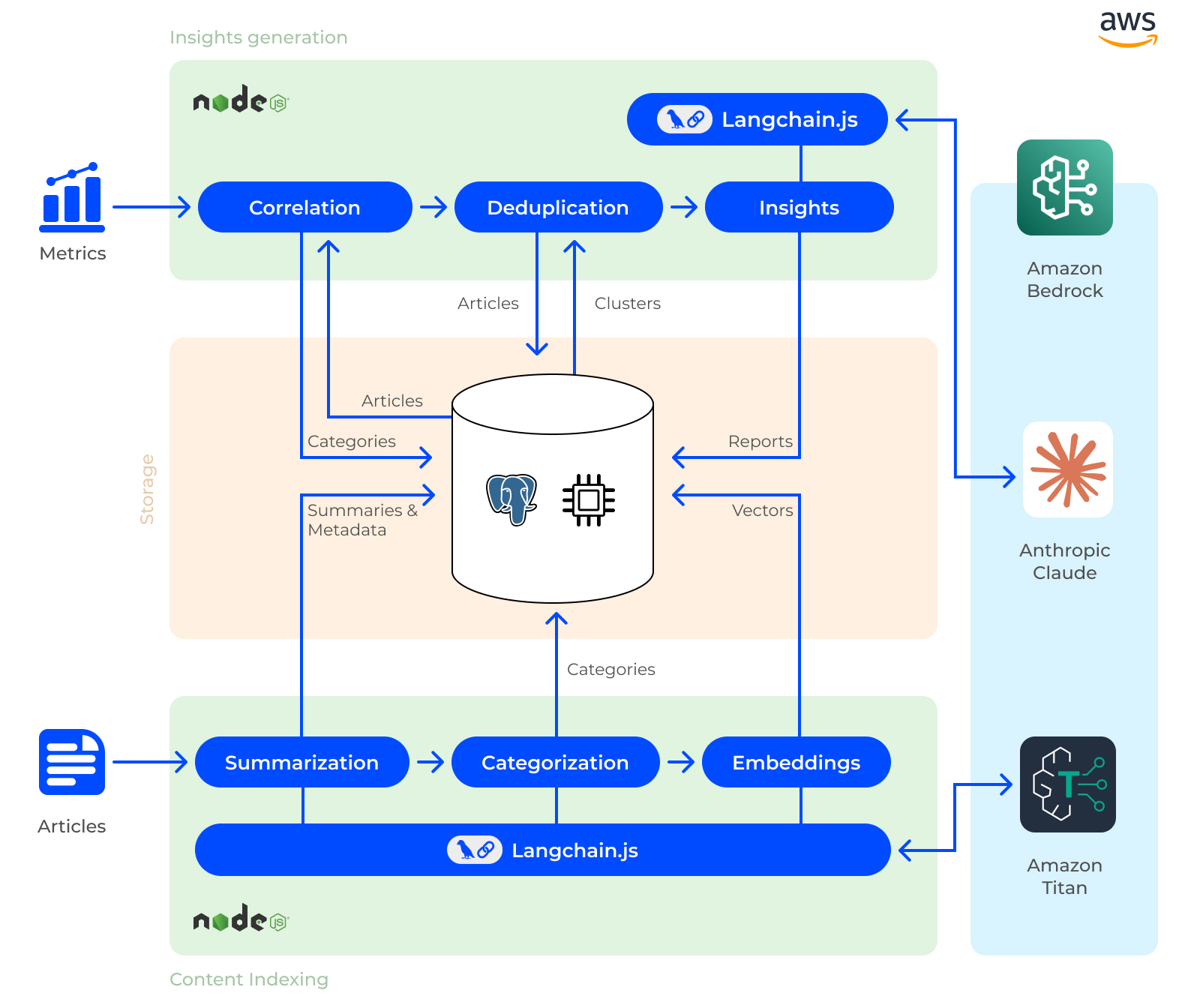
We developed a proprietary AI-based algorithm for content analysis capable of summarizing, categorizing, and deduplicating content. We also aligned article categorization with metric changes to enable metric correlation. Additionally, we implemented automated reporting with AI-generated reports and recommendations based on metrics and article excerpts. Our tech stack includes Amazon Bedrock, Anthropic Claude, Amazon Titan, Langchain.js, and PostgreSQL with pgvector.
Value delivered:
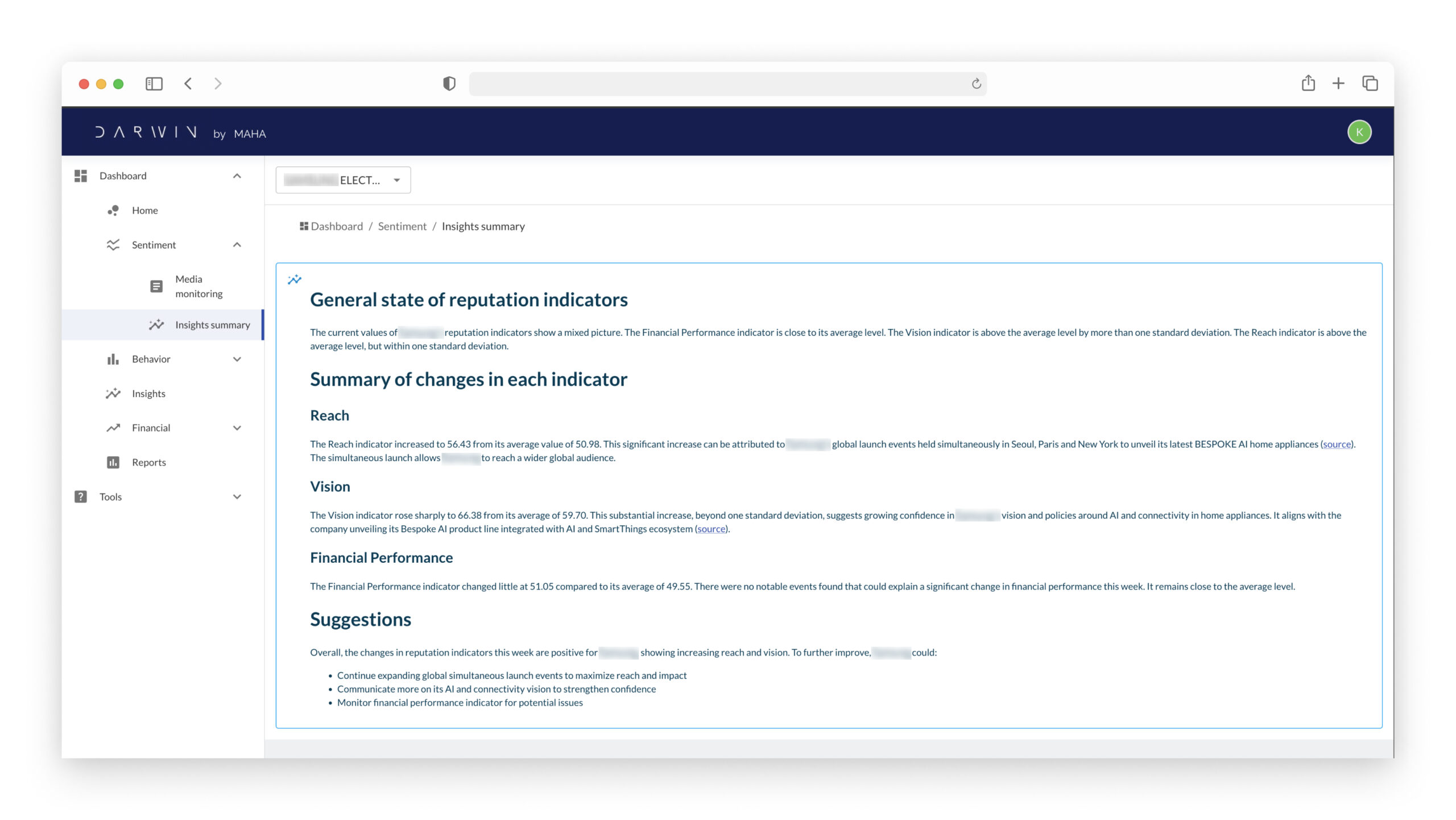
- Improved article relevance and text generation for personalized customer dashboards.
- Enabled understandable and relevant reports.
- Increased cost-efficiency.
Cooperation models:
Managed Delivery
Expertise:
AI/ML
GenAI
Web development
Technologies:


Facing similar challenges? Contact our experts now.
Zoolatech Approach
Value Delivered
Contact us
Let's build great
products together!
products together!