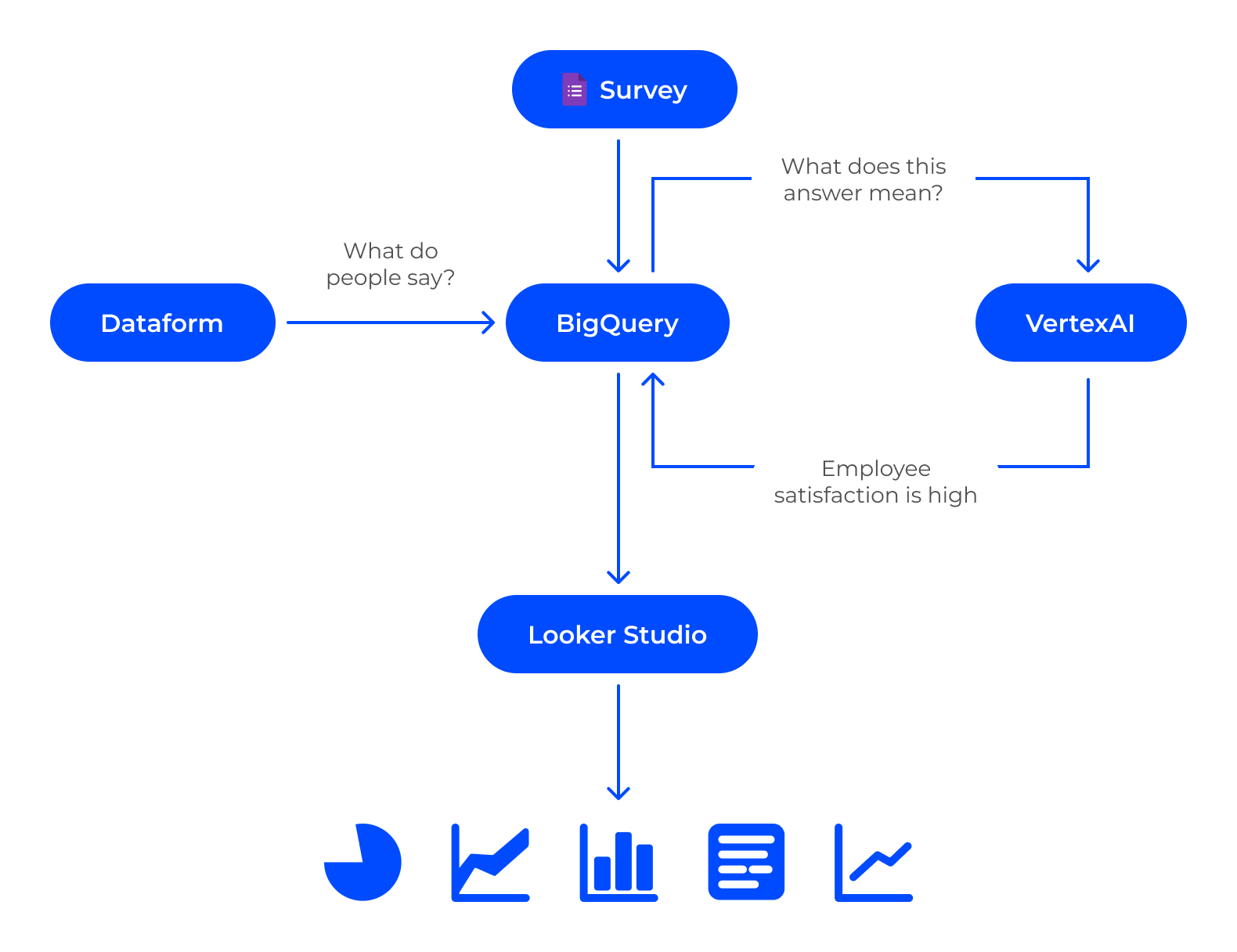
- Consolidation of all data, the analysis of which is necessary, into a DWH
- Introduction of automated data pre-processing using Google Dataform
- Implementation of data processing functions and patterns using LLM

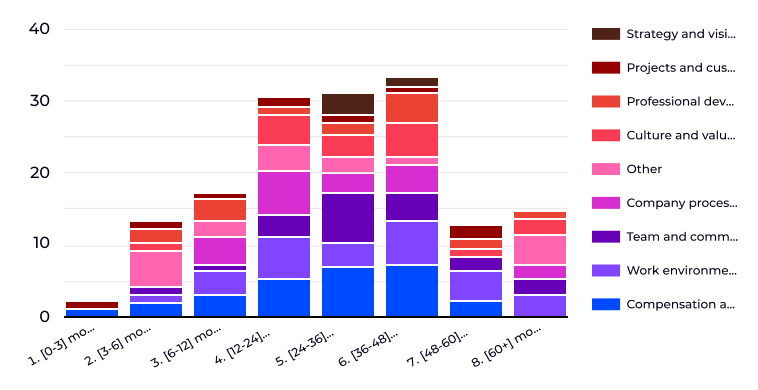
For example, histograms that classify text responses. To do this, the LLM was first tasked with identifying common categories from the mass of responses. Then, once the final list of categories was compiled, the LLM classified the responses according to the resulting list.

This method is used to create generalized recommendations and reviews.
Summarization and anonymization of responses. In cases where it is necessary to not only analyze each answer, but also display them, this helps to understand the answers and suggestions in more detail. It is possible to maintain anonymity and remove identifying information and style of the message.

This is an alternative to frequency analysis when it is impossible to clearly categorize responses, but you want to visualize trends. To obtain them, the LLM is tasked with reducing each answer to one or two words.

Thus, it is possible to conduct analysis based on the number of respondents in each group, or even use different analysis methods for each group.
products together!