



Apache Kafka is a widely used distributed streaming platform for real-time data processing. According to Confluent, 150,000 organizations use Kafka.
However, managing and maintaining Kafka can be challenging due to its complexity and the need for specialized skills. Kafka developers are in high demand to ensure the integrations are seamless, secure, and scalable; and finding qualified engineers can be a tough task.
That’s why many industry leaders choose to outsource designing, building, and maintaining their Kafka-based applications to a reliable technology partner. That allows tapping into a global talent pool, saving costs, and accelerating deployment.

The data from such sources as PayScale, Indeed, Upwork, SalaryExpert, TopTal show that the average rate of a software engineer in 2023 in Eastern Europe or Latin America is approximately 15-20% lower than in the USA, for instance.
What’s more, IT outsourcing and partnering with remote Kafka developers allows you to reduce recruitment and administration overhead as you don’t need to hire, train, and retain the specialists. And it allows you to scale up or down your development capacity easily.
On top of that, if you need additional expertise, for instance DevOps, Data Analytics, QA or any other – your outsourcing partner will help you to find the necessary specialists easily and quickly.

It outsourcing can help you reduce costs and scale up fast. But how to find and choose the remote Kafka developers you can rely on and who can both understand and help you meet your specific business goals?
Let’s find out.
How to Choose Top Kafka Developers to Optimize Costs and Scale Easily
As a company that has worked with many industry leaders in the US and Europe (e.g., Nordstrom, Credible) to build event-driven architectures using Kafka, here are some of the key aspects we recommend paying attention to when hiring your Kafka developers:
- Targeted at scalability, flexibility, and high-availability: Your Kafka-based system needs to be scalable and flexible to meet your evolving business needs. You should choose a team of Kafka engineers who have experience building future-proof systems that can be easily scaled up or down and are flexible enough to adapt to changing requirements.
- Able to achieve the balance between consistency, scalability, and high availability in a low-latency, real-time operating environment.
- Strong understanding of Kafka architecture: Kafka developers should have a deep understanding of Kafka’s architecture, including its core components, such as topics, brokers, and producers/consumers.
- Expertise in Kafka API: Kafka engineers should have experience working with Kafka API, including the Producer and Consumer API, Kafka Streams API, and Kafka Connect API.
- Proficiency in programming languages: Kafka developers should be proficient in programming languages such as Java, Scala, and Python, which are commonly used in Kafka development.
- Understanding of distributed systems: Kafka is a distributed system, so Kafka engineers should have a strong understanding of distributed systems and be familiar with concepts such as replication, partitioning, and fault tolerance.
- Knowledge of DevOps and CI/CD: Kafka developers should have experience with DevOps practices and CI/CD pipelines, including automation, testing, and deployment.
- Familiarity with monitoring and logging tools: Kafka engineers should be familiar with monitoring and logging tools, such as Kafka Manager, Grafana, and Elasticsearch, to ensure the smooth operation of Kafka-based systems.
- Excellent problem-solving and debugging skills: Kafka developers should be able to quickly identify and solve problems in Kafka-based systems and have strong debugging skills to troubleshoot issues.
- A portfolio of successful case studies.
Your Kafka engineers should know how to tackle such challenging aspects as deduplication, tokenization, the right event ordering, better user experience, custom metrics, scaling-up and scaling-down, resources and costs optimization, further Data Analytics capabilities, and many more.

When contacting and shortlisting your potential Kafka development partner, we also recommend you take into account such aspects as:
- what pricing and cooperation models they offer and their ability to adjust these models to your specific needs;
- whether they have a strong employer brand to attract the best specialists in the local market;
- if they offer professional development programs to grow and retain their talent;
- do they have many long-term partnerships in their portfolio;
- legal aspects of your cooperation;
- how they ensure a clear company structure and transparent communication;
- how they set up Agile processes.

Featured Success Stories of Partnering with Remote Kafka Developers
1. Building a Kafka-based integration hub for a jewelry giant
Business challenge: Seamless integration between diverse systems
The company needed to ensure seamless integration between multiple diverse systems, making data exchange between them fast, efficient, and accurate.
To solve legacy problems and build a solid foundation for digital transformation, the company decided to develop a scalable integration hub based on Event-Driven Architecture and Kafka.
The ultimate business goals of the solution were to:
- ensure seamless integration between many different systems, making data exchange between them fast, efficient, accurate, and reusable;
- integrate new and old markets, unify functionality, and standardize data objects;
- shift from many-to-many to many-to-one;
- provide customers with personalized, omnichannel user experience (e.g., order online – pick up in store);
- enable omnichannel inventory management and more efficient logistics and transportation management ;
- provide real-time visibility into all business processes (via dashboards and BI reports);
- ensure future-proof scaling;
- reduce development and maintenance costs;
- optimize performance.
And they needed a reliable technology partner with expertise in EDA and retail.
Zoolatech approach: From in-depth analysis to implementation
1. Product discovery phase
We analyzed the legacy system and its limitations as well as investigated the current and upcoming needs of the company. With a precise focus on the company’s business goals, we helped our client choose the most suitable tech stack and architecture for the platform to reduce maintenance costs, withstand high load, and mitigate risks.
2. PoC, MVP, and further development
We provided the company with a strong engineering team. The team built a PoC and MVP and proceeded with further product development. Also, the Zoolatech team prepared a set of clear engineering standards to drive operational excellence and optimize costs.
3. Best DevOps practices
We helped our client to streamline, unify, and standardize all DevOps processes as well as apply best DevOps practices.
4. Site reliability engineering
Our site reliability engineers analyze Pandora’s IT ecosystem, monitor their software reliability in the production environment, and help make Pandora’s software systems more reliable and scalable.
5. Omnichannel inventory management
We help our partner integrate their ERP, Transportation management, and Warehouse management systems and make the data exchange between these diverse systems fast, efficient, and consistent. It helps to provide real-time or near-real-time visibility into all inventory levels and optimize logistics and transportation management.
Also, we help accelerate adoption of the platform among other teams by building templates, writing documentation, and transferring knowledge. What’s more, it helps to considerably reduce development time and costs.
To make the platform more efficient, scalable, and secure, our team has extended the Apache Kafka integration hub with additional custom services and systems, such as:
- Nexus management system. It comprises an internal storage for history tracking and UI to search and debug single events. The system helps to improve the user experience for all end-users of the platform.
- Deduplication service. It helps to eliminate excessive copies of data and significantly decrease storage capacity requirements.
- Tokenization service. It allows replacing sensitive data with tokens, improving data security, and remaining compliant with regulatory requirements across markets.
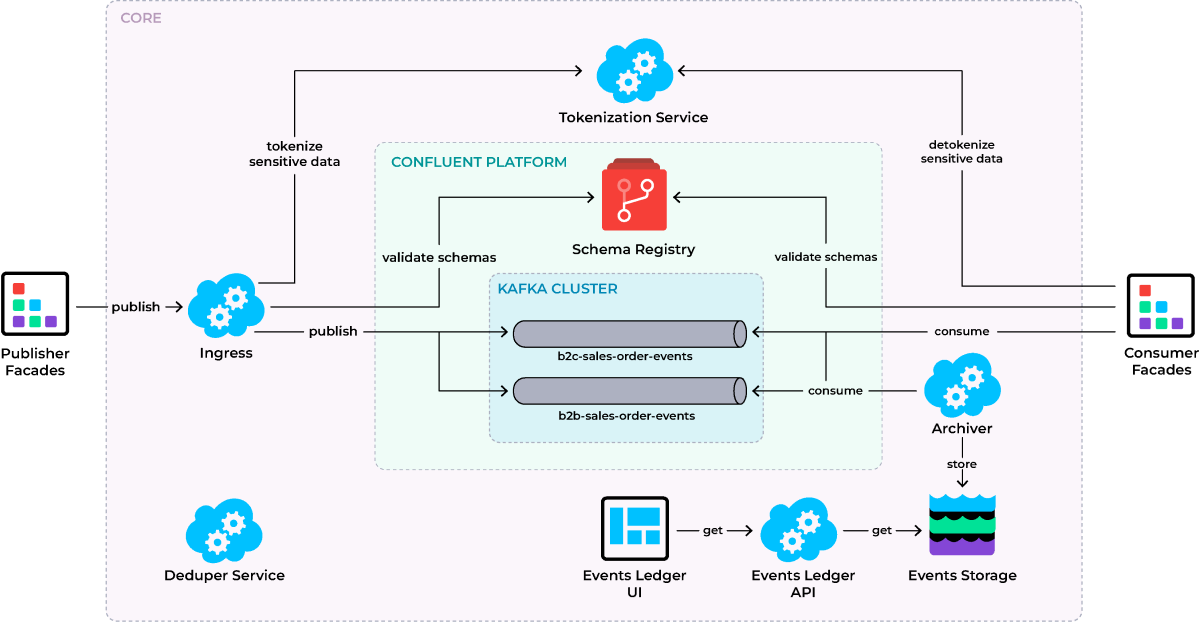
Value unlocked: Increased scalability, reliabilility, and efficiency
The new integration platform helped our partner increase scalability, efficiency, and data integrity. The product created a digital foundation for integrating all business processes and unlocking the value of real-time data analytics.
It helps our partner to:
- ensure seamless integration between multiple Pandora’s systems, making data exchange between them fast, efficient, and accurate;
- decrease latency from 36 hours to milliseconds and improve data accuracy;
- unlock the value of real-time data analytics and provide visibility into all business process;
- build a solid foundation for Advanced Data Analytics and AI;
- provide customers with omnichannel user experience;
- increase fault-tolerance;
- enable more efficient logistics and transportation management;
- reduce maintenance costs and complexity;
- ensure future-proof scalability.

Read the success story in detail.
2. Helping a Fortune 500 retail company optimize cloud costs
Business challenge: Increasing the scalability and efficiency of a critical service
The company needed to redesign a critical service to increase its durability, scalability, and efficiency, while removing dependencies on the services planned for deprecation. The legacy service needed to be replaced with a new one with no downtime.
Zoolatech approach: A thorough analysis and new architecture design
We have helped our partner to design the new service architecture, establish the development process, plan and execute the transition to the new version with no downtime, ensuring data consistency and performance metrics.
Initially, the design of the Order-Invoice Kafka Producer (OINK) was complex, error-prone, and difficult to debug. It consumed 10 types of events, had the algorithm of event joining with the 8-day time frame only, partial DLQ coverage, and often missed events that were tough to identify.
Service performance was limited to 21k of the RTCIM events (main event type) per hour on 12 pods.
In general, OINK v1 suffered from a significant lag (~400). It processed:
- 21k rtcim/hour (12 pods);
- 1.75k rtcim/hour (1 pod);
- 29 rtcim/min (1 pod).
OINK v1:
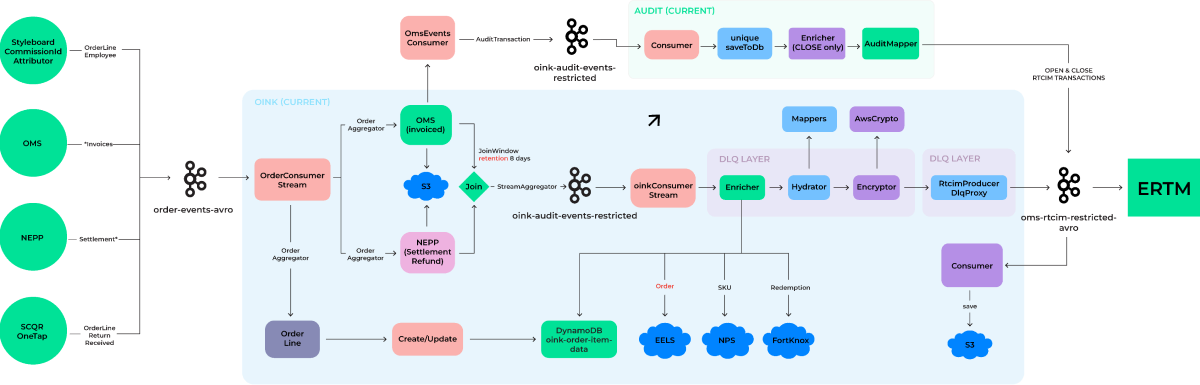
Implementation
First, Zoolatech helped the client to decouple OINK from the system called OMS and created OINK v2, which was completely compatible with version 1. The quality criterion was the inability of downstream systems to recognize RTCIM parcels created by different OINK versions.
As a part of decoupling, Zoolatech created the new testing service “comparator,” which compares the RTCIMs generated by version 1 and version 2.
Also, we created a reliable method of redirecting production traffic from Oink version 1 to version 2. The second version of OINK was tested on the production environment in a shadowed mode, and several upstream issues were identified and resolved.
During this task, the Zoolatech team worked closely with OMS, Payment, Tax teams (upstream), ERTM (Enterprise Retail Transaction Management), and Sales Audit departments (downstream).
What we have achieved together
- Thanks to loose coupling in the new event-driven architecture, we easily changed the dependency on 4 upstreams to just one incoming stream of events.
- Thanks to using the right number of Kafka topic partitions for pod scaling, we achieved seven times faster RTCIM events processing with 12 pods.
- We developed a DLQ layer all over the OINK v2 service components thanks to Kafka Connect’s DLQ support, ensuring that no single event was missed during processing.
- We helped our partner to significantly reduce cloud costs. Three pods of OINK v2 perform approximately the same as 12 pods of OINK v1. So, we can either process data faster with the same resources or reduce costs by approximately four times. Memory consumption is 4+ times less than in the previous version, considering the same number of pods.
OINK v2:
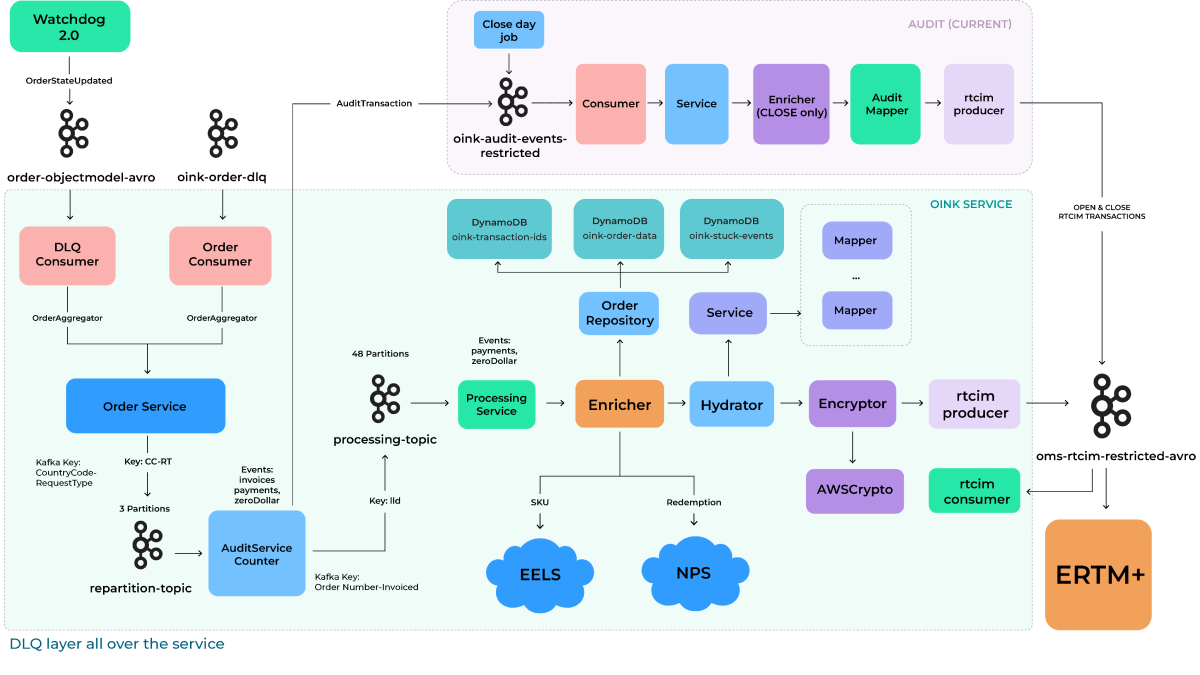
Peak throughput:
- 150k rtcim/hour (12 pods);
- 12.5k rtcim/hour (1 pod);
- 208 rtcim/min (1 pod).
Processing: Three pods of OINK v2 equals 12 pods of OINK v1.
Total Memory Usage (RAM): 14.4GB (Oink2) vs. 60GB (Oink1) / 12 pods.
Value unlocked: Reduced cloud costs and improved performance
Zoolatech helped the company to design a new service architecture, establish the development process, plan and execute the transition to the new version with no downtime, ensuring data consistency and performance metrics.
- A high-load, robust, and scalable service working 7 times faster than the previous version.
- Elimination of dependencies on services planned for deprecation.
- Successful replacement of the legacy service with the new one with no downtime.
- Cost reduction. 3 pods of OINK v2 perform approximately the same as 12 pods of OINK v1, reducing costs by approximately 4 times.
- Optimization of cloud resources and maintenance costs, including incident analysis and further development costs.
- Reduction of memory consumption.
- Identifying and resolving several issues in the client’s upstream data.
- Helping our partner launch the deprecation of obsolete systems and achieving further cost-savings on the infrastructure.
Overall, our partner achieved a more efficient and reliable critical service, leading to cost savings, increased customer satisfaction, and business performance.

Why Choose Zoolatech as Your Kafka Engineering Partner
Zoolatech is a global software development company with HQ in the USA and development centers in Poland, Ukraine, Mexico, and Turkey. We help businesses drive their digital acceleration with EDA, microservices, Cloud, DevOps, Data Analytics, and more.
- Build your custom Kafka integrations from scratch while mitigating risks and focusing on ROI.
- Audit and redesign your Kafka integrations to optimize costs and performance.
- Scale your development capacity and solve your technology problems faster.

Benefit from years of experience:
- added value with each single technology;
- universal integration landscape, yet fully customized for your business needs;
- continuous improvement in each area of operation;
- 450 engineers; development centers in Poland, Ukraine, Mexico, and Turkey;
- experienced business analysts, Kafka architects and engineers;
- focus on long-term partnerships;
- 90% senior and middle software engineers;
- seamless team integration;
- fast and flexible team augmentation.
Need to augment your Kafka development expertise now? Please contact our specialists!




















