



Enterprise retail data architecture has a structural problem.
Two parallel systems, a data lake and a warehouse, never fully synchronize. That synchronization burden costs retailers time, money, and data accuracy.
In practical terms, retailers stop maintaining separate copies of the same data for analytics, dashboards, and AI models.
This article delivers the framework for evaluating that architectural decision.
The Structural Problem with Traditional Retail Data Architecture
Enterprise retail data architecture accumulated its core problem over a decade. Two separate systems emerged: a data lake for raw storage and a warehouse for analytics. The process of constantly moving and synchronizing data between systems became the most fragile part of the architecture.
Data lakes stored raw POS, WMS events, and clickstream data cheaply at scale. They lacked built-in safeguards for keeping rapidly changing data consistent during simultaneous updates. Concurrent writes produced inconsistent state and stale queries.
Data warehouses provided reliable data consistency, structured governance, and fast SQL analytics. They required data to be cleaned, transformed, and loaded before analysts could use it.
The result: both systems held different versions of the same data. Synchronization was a permanent operational burden. ML models and dashboards returned conflicting figures.
Two-stack vs. Databricks Lakehouse for retail:
| Dimension | Data Lake + Warehouse | Databricks Lakehouse |
| Data copies | Multiple: lake, warehouse, data marts | One: Delta Lake as single source |
| Freshness | Hours to days due to synchronization delays | Sub-minute with DLT CDC |
| ML and BI access | Separate systems, different data | Same Delta table, same moment |
| Governance | Fragmented across tools | Unity Catalog: one layer |
| Cost model | Two compute bills plus ETL overhead | Single platform, scale to zero |
What the synchronization burden costs enterprise retailers:
- Duplicate data pipelines copying the same transaction data across multiple systems
- ML models running on week-old warehouse exports, not live data
- Data scientists and analysts getting different revenue figures
- Every new use case requiring architecture changes across multiple layers
As a certified Databricks partner, Zoolatech helps enterprise retailers modernize fragmented data platforms into unified Lakehouse architectures built for real-time analytics and AI.
Why Databricks Is the Enterprise Standard for Retail Data Platforms
Databricks earned the highest Ability to Execute position in the 2025 Gartner Magic Quadrant for Data Science and Machine Learning Platforms.
It is Databricks’ fourth consecutive Leader recognition and highest-ever placement. The Databricks Lakehouse for Retail program counts Walgreens, H&M Group, and Columbia among production adopters.
Databricks retail solutions vs. the two primary alternatives:
| Capability | Databricks | Snowflake | Microsoft Fabric |
| Data processing | Real-time, batch, SQL with native ML | Optimized for batch and SQL | Unified lake with real-time analytics |
| AI/ML | Full MLOps lifecycle built in | Depends on third-party integrations | Connects to Azure AI services |
| Open standards | Delta Parquet, multi-cloud ready | Proprietary storage format | Azure-coupled, constrained multi-cloud |
| BI reporting | Any tool; AI/BI Genie included | Power BI and Tableau connectors | Power BI native only |
| Choose when | Complex data plus AI/ML workloads | Pure SQL analytics, simpler stack | Already on Microsoft 365 |
The gaps the Databricks retail industry solutions close on a single platform:
- Data silos: Delta Lake ingests structured, JSON, and EDI source types into one governed layer.
- Slow time-to-insight: Automated streaming pipelines keep dashboards and AI models updated in near real time.
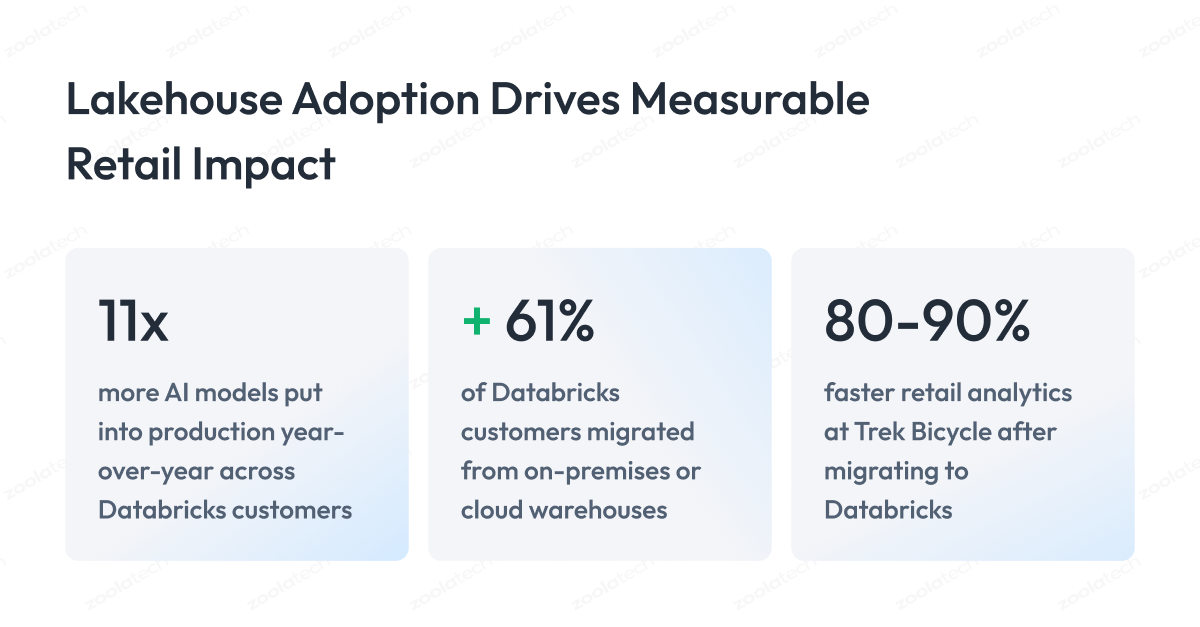
- ML operationalization: MLflow helps teams move AI models from testing into production faster; the customer ratio improved from 16:1 to 5:1.
- Infrastructure cost: serverless SQL Warehouses scale to zero when idle; Delta on ADLS runs at object storage rates.
- Data quality failures: DLT expectations quarantine violating records before Gold; Medallion creates an auditable chain.
Enterprise retailers running on Databricks
Enterprise retailers are using Databricks to reduce reporting delays, simplify fragmented data architectures, and support AI-driven operations at global scale.
- Walgreens processes approximately 40,000 pharmacy and inventory events per second across 9,000+ locations, supporting real-time operational workflows and analytics.
- Trek Bicycle modernized analytics across 450 global stores, reducing ERP replication from 48 hours to near real time and accelerating retail analytics by 80–90%.
- H&M Group adopted Databricks Lakehouse architecture across operations in 75 markets, enabling enterprise-scale AI and self-service ML deployment capabilities.
These implementations reflect a broader retail shift toward unified Lakehouse platforms capable of supporting real-time reporting, governance, and AI workloads within a single architecture.
Zoolatech + Databricks: Enterprise Retail Modernization Partnership
Being a member of the Databricks Brickbuilder Partner Network, we help retailers move from fragmented analytics ecosystems and isolated AI experiments toward scalable, production-ready data platforms.

The partnership combines Databricks’ Lakehouse and AI capabilities with our experience modernizing complex enterprise retail environments across data, analytics, governance, and reporting.
Together with Databricks, we support initiatives such as:
- Lakehouse architecture modernization
- Real-time analytics and AI enablement
- Power BI and Azure ecosystem transformation
- Centralized governance with Unity Catalog and Delta Lake
- Enterprise-scale implementation with measurable business outcomes

Built around Databricks’ focus on specialization and production-grade AI delivery, the Brickbuilder program reinforces our expertise in designing scalable, AI-ready retail platforms capable of supporting real-time operations, advanced analytics, and long-term modernization initiatives.
What the Databricks Lakehouse for Retail Actually Is
The Databricks Lakehouse for retail solves the two-stack problem at the storage layer.

Delta Lake adds reliability, governance, and historical version tracking directly to cloud storage. One Delta table serves Power BI, ML jobs, Kafka pipelines, and audits simultaneously.
The five platform components that matter most in retail:
- Delta Lake: merges CRM, POS, and loyalty data into one customer record without full table rewrites. Lets teams review how order data looked at any previous point in time for audits or dispute resolution.
- Unity Catalog: masks customer PII by role; analysts see hashed IDs while compliance teams access full records. Grants supplier access to specific tables without workspace access.
- Photon Engine: accelerates large retail analytics queries, even across massive sales datasets. Category managers recalculate full-catalog markdown impact without overnight scheduling.
- SQL Warehouses: store operations managers query curated retail datasets directly in Power BI. No data export, no copy, no data team involvement required.
- MLflow: tracks 50-plus forecast variants per SKU and promotes the best model to production in one step. Deploys real-time pricing models as REST endpoints.
The Medallion Architecture: How Retail Data Moves from Raw to Reliable
The Medallion architecture is the standard data organization pattern on Azure Databricks.
It preserves raw data exactly as received while giving consumers clean, reliable aggregates. Three layers enforce progressively higher data quality on Delta Lake.
- Bronze, raw ingestion: stores POS transactions, WMS events, CRM records, and clickstream exactly as received from source systems, with no transformation applied.
- Silver, cleansed and conformed: cleans, validates, and updates incoming data before it reaches dashboards or AI models; quarantines bad writes before they reach analysts or models.
- Gold, business-ready aggregates: builds SKU-level sales, customer 360 profiles, and margin tables for direct consumption by Power BI and ML models.
What the Medallion structure protects against:
- Bad data reaching BI dashboards before quality checks run
- Conflicting customer records from separate ingestion pipelines
- ML models training on corrupt or incomplete upstream inputs
- Audit failures from untraceable data lineage
Zoolatech and Pandora: Consolidating a Five-Layer Architecture onto Databricks
Pandora is one of the world’s largest jewelry retailers, operating globally across retail, e-commerce, and customer analytics environments.
Approximately 100 source systems fed a five-layer data architecture. That architecture was expensive, slow, and incompatible with real-time AI requirements.

Zoolatech, as a certified Databricks partner, was engaged to redesign and consolidate this.
The before-state
The as-is architecture produced four compounding pain points:
- Dual compute: Azure Synapse for SQL alongside per-product-line Databricks workspaces; two billing models, two governance approaches, no unified lineage.
- Dual ingestion: Kafka for streaming plus Azure Data Factory for batch; two pipeline surfaces with no consolidated monitoring.
- Analysis Services dependency: an extra transformation layer between data and Power BI adding latency, cost, and cascade risk to every change.
- Report dependency: approximately 500 global Power BI reports tied to Analysis Services; any change propagated unpredictably across the estate.
The to-be state
Zoolatech designed the target architecture around five decisions:
- Delta Lake and Medallion: Bronze, Silver, and Gold zones replacing ad-hoc ADLS storage; every dataset follows an auditable, reprocessable lifecycle.
- Unity Catalog: centralized governance for 5,000-plus analytics users globally; row-level security and PII masking replacing manual processes.
- Kafka-only ingestion: Kafka extended to cover streaming, bulk, and master data loads, retiring Azure Data Factory entirely.
- Databricks SQL and Power BI direct: approximately 500 reports connected to Gold tables, eliminating Analysis Services entirely.
- Databricks Workflows: full pipeline from Kafka ingestion through Bronze, Silver, Gold to Power BI refresh in one place.
Migration sequencing and risk mitigation
- Architecture defined first: no workload moved until the target state was documented, approved, and validated against all dependencies.
- Synapse decommission behind SAP S/4HANA: finance-domain reporting continuity protected until the upstream ERP migration was stable.
- Analysis Services phased by domain: lowest-dependency reports migrated first; each domain validated before moving the next.
The result is a reduction from five architectural layers to three. Single compute, single governance, real-time analytics across all global operations.
Measuring the Lakehouse Investment: A Retail KPI Framework
Lakehouse consolidation requires measurement at two levels: operational efficiency and commercial impact. The metrics below apply to enterprise retail data programs before, during, and after migration.
| Category | Metric | Why It Matters at Enterprise Retail Scale |
| Data freshness | Source event to Gold table latency | Directly impacts decision quality across all workloads |
| Platform cost | Compute spend vs. pre-migration baseline | Quantifies consolidation ROI against investment case |
| ML productivity | Experiment-to-production model ratio | Measures AI operationalization maturity improvement |
| Query performance | P95 response time on Gold tables | Affects analyst productivity and BI adoption rate |
| Visibility and control across data assets | Percentage of data assets with tracked lineage | Regulatory and audit readiness across all regions |
| Pipeline reliability | Successful job completion rate | Operational stability of core retail processes |
Decision Framework: Is Your Retail Stack Ready for Lakehouse Consolidation?
Consolidation readiness is an architecture assessment, not a technology decision. These five questions identify readiness and correct migration sequence.
- How many data copies exist? Each copy is a synchronization cost and a source of conflicting truth across teams.
- What is source-to-dashboard latency? Hours or days indicates the architecture constrains the business, not the tooling.
- How long from ML experiment to production? Weeks or longer signals MLOps infrastructure debt the Lakehouse directly addresses.
- How many compute platforms does the team manage? Each additional platform multiplies governance overhead, cost, and operational risk.
- What breaks if you remove one layer? The answer reveals which dependencies are requirements and which are accumulated complexity.
Conclusion
The two-stack architecture fails at scale. More tools cannot fix a structural problem. The Databricks Lakehouse eliminates it at the foundation.
Key findings:
- The ETL burden is architectural, not an operational issue better tooling resolves
- Delta Lake replaces two parallel systems with one ACID-compliant layer
- Medallion enforces data quality before it reaches analysts or models
- Unity Catalog centralizes governance, lineage, and PII masking in one layer
- Pandora is consolidating from five architectural layers to three
- Production retailers report 80–90% faster analytics and real-time event processing at scale
Questions You May Have
What is the Databricks Lakehouse for retail?
The Databricks Lakehouse unifies data lake and warehouse into one Delta Lake layer. It eliminates the ETL pipelines that traditional two-stack architectures require.
What is Medallion architecture?
Medallion organizes data into Bronze, Silver, and Gold layers on Delta Lake. Each layer enforces higher data quality before downstream use.
Databricks vs Snowflake for retail?
Choose Databricks when you need ML, streaming, and SQL on one open platform. Choose Snowflake for pure SQL analytics without significant ML requirements.
What does Unity Catalog solve?
Unity Catalog centralizes access control, lineage, and PII masking across all workloads. It replaces fragmented governance from separate lake and warehouse systems.
How long is a Lakehouse migration?
Phased migrations typically run 12 to 24 months. Architecture design must complete before any workload moves.
What is a retail solution accelerator?
A solution accelerator is a prebuilt implementation of one specific retail use case. It reduces development effort by 25–50% versus building from scratch.




















